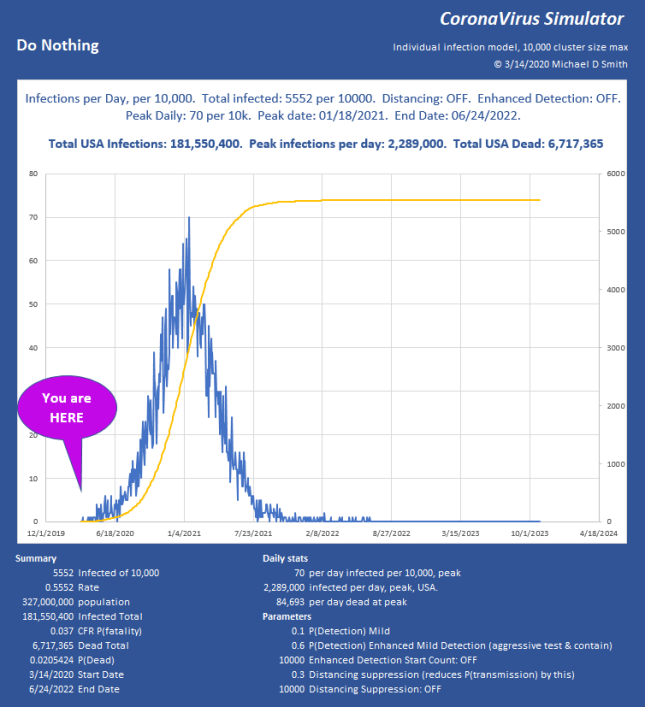
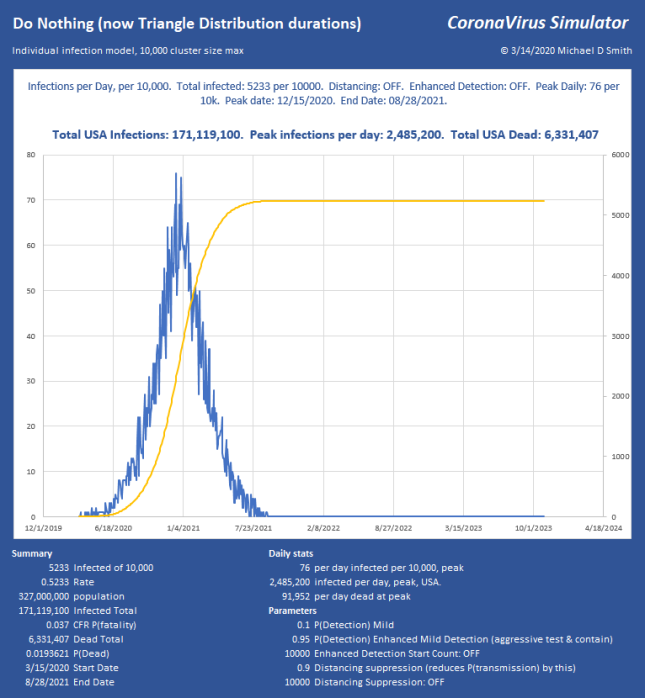
Last week I posted a bit about my model that shows infection progression on an individual basis, with a population size of 10,000. I have added some new features and explored a lot of factors now. I’m particularly interested in what level of suppression can be applied to avoid constraints like ICU bed capacity or PPE. The disease continues to progress exponentially, while our efforts to measure and contain it seem to be linear. I don’t think many people really understand what is implied if you just let a situation like that run free. It is a horrific outcome, and it takes a long time too:
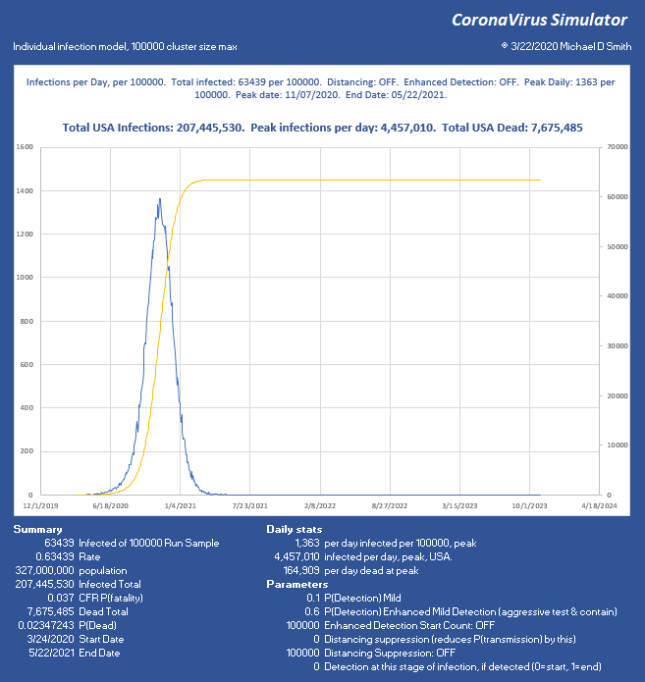
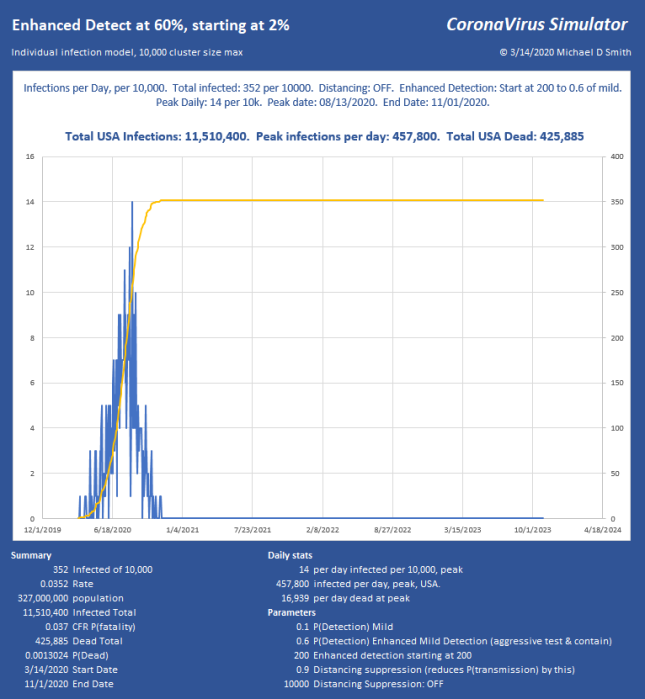
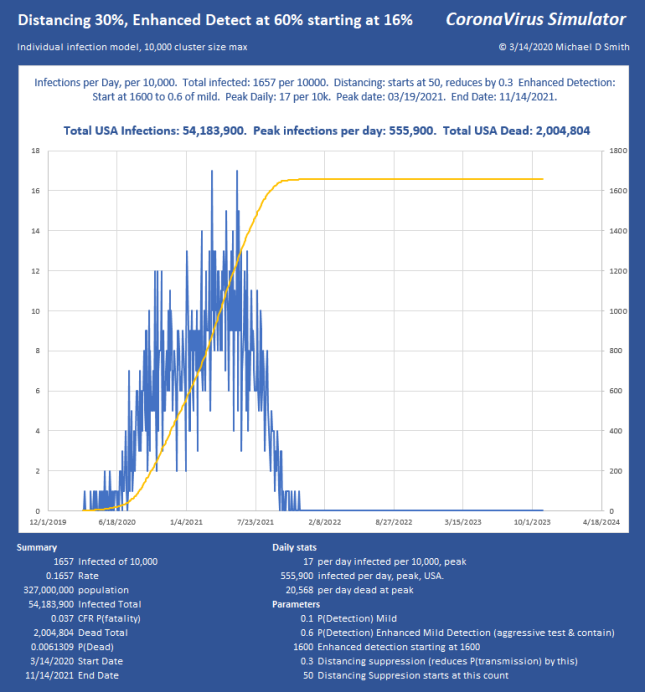
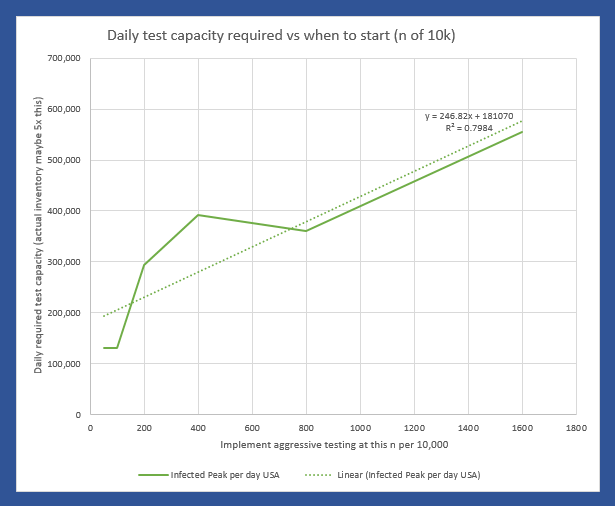
For a little perspective, find the peak number of infections per day, USA on that chart. About 6% will need ICU, so multiply by 0.06 . That is how many intensive care beds you need PER DAY, so in this case, 267,420 per day. The USA has maybe 100,000 ICU beds, of which about 68% are typically full, leaving us 32,000 beds total, which will already be overflowing from yesterday and the day before in the “Do Nothing” case. For the people who cannot be treated… that is not going to be a nice way to go. If severe cases take about 31 days to resolve, you really can handle only about 1000 patients per day for 32 days as they rotate in and out. In the USA. That’s it. You aren’t going to get to 267 times that in ventilators. Ever. Not in PPE either. This explains why aggressive distancing has been employed here in the USA lately, with leaders begging us to pay attention.
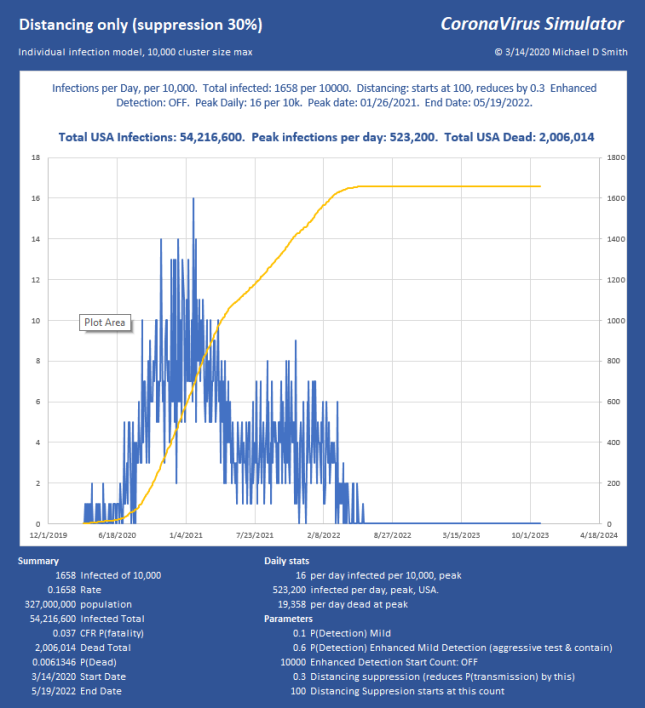
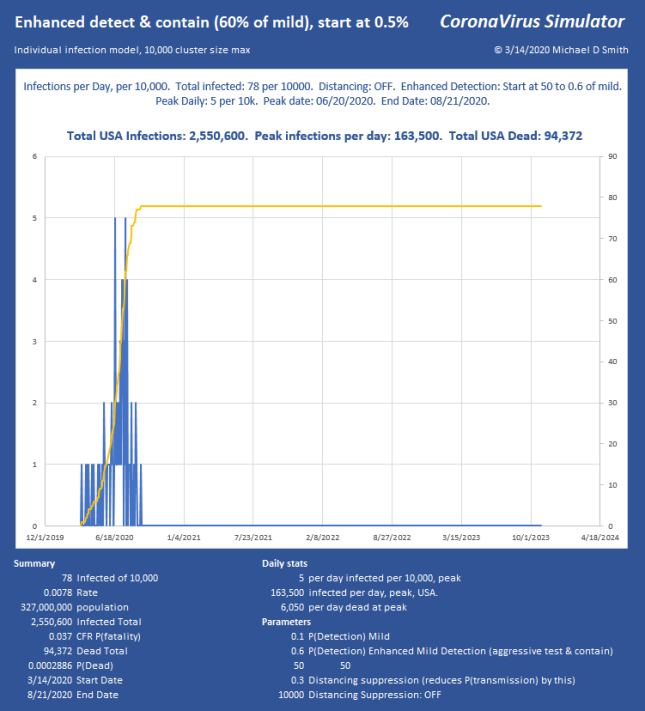
So, how do we keep total ICU bed demand below 1000 per day? Slam the door shut. This is what China did. Without using any aggressive detection, and assuming all that we can do is separation, I use a factor that simulates the effectiveness of suppression. So 70% means I reduce the chance of infecting the next victim by this much. If you aggressively either contain (which requires detection) or separate (which doesn’t), it can be over with and fizzle out in only a few generations. Here is 70% reduction in transmission, starting at an infected count of 250 out of 1,000,000:
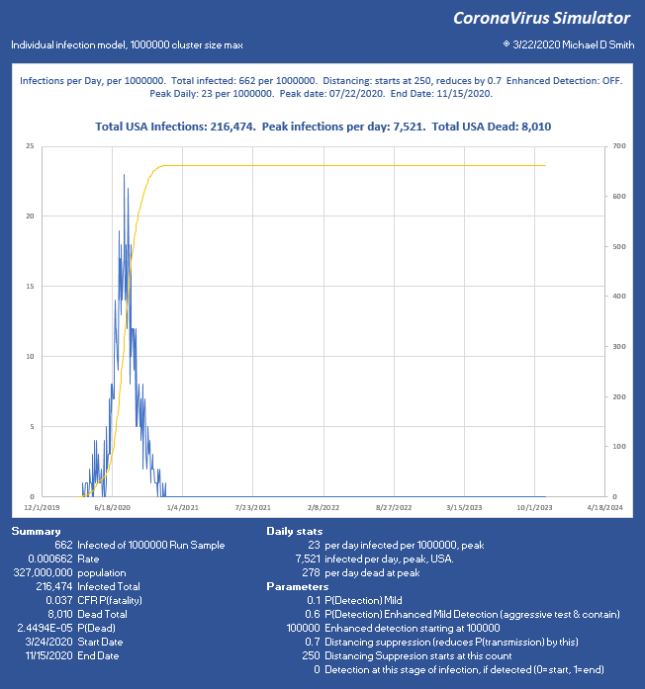
Good news, we keep it at 0.066% infected total. We started interfering at 250, but it reached 662 infected, so it lingered a few generations before collapsing and still infected 412 more. The peak is 7520, which (times 0.06) is below our target of 1000 ICU beds per day, so we can use even less suppression.
I chose 250 starting count because we now have some information about the base infection level. The CDC reported today that about 1 in 1000 New York City dwellers is currently infected. Assuming a doubling every 3 days, and that we applied separation about a week ago (about 2 doublings ago), I will take a population of 1 million, and show what only 40% effectiveness of separation does at a starting count of 250 (1,000,000 * 0.001 / (2^2)).
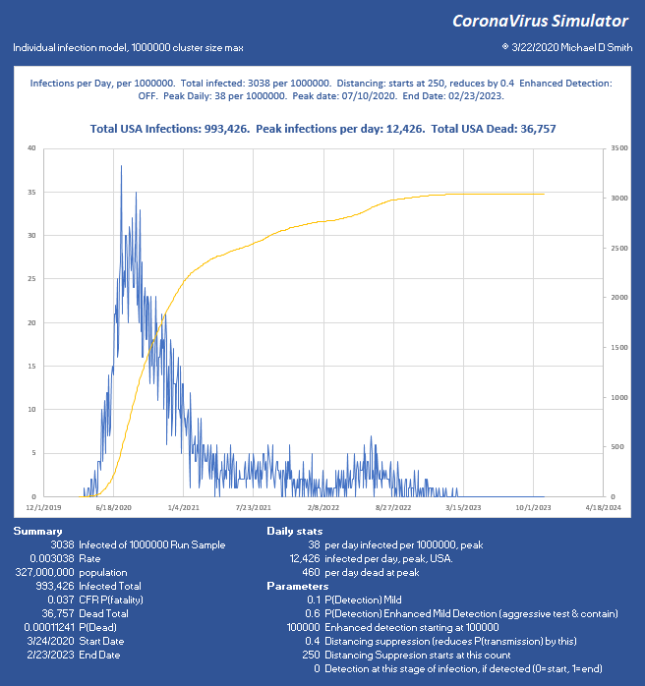
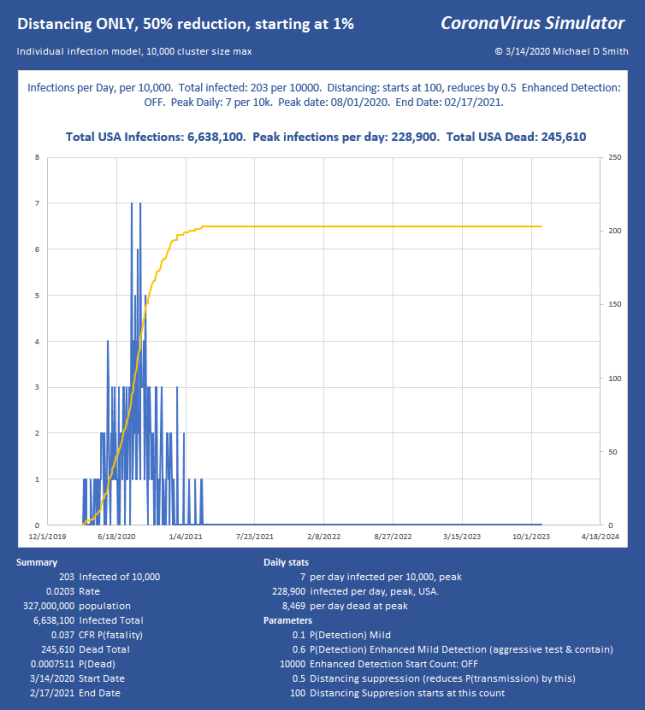
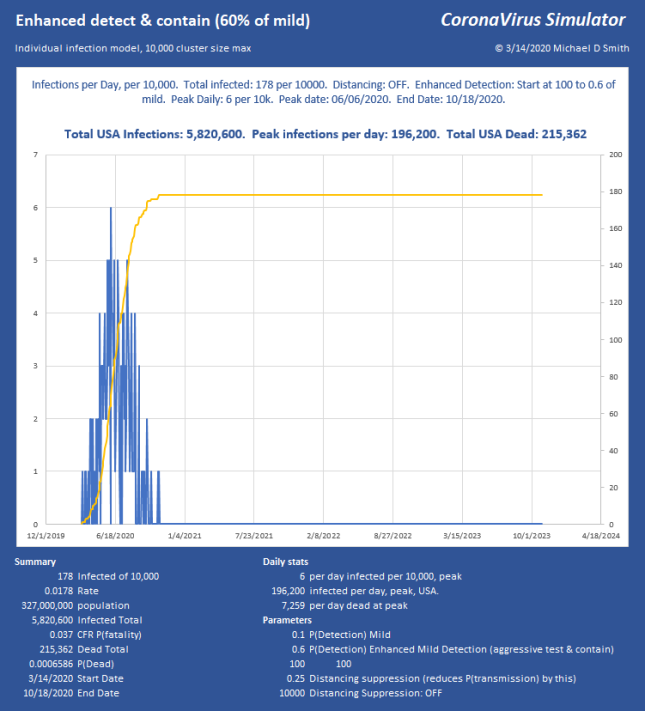
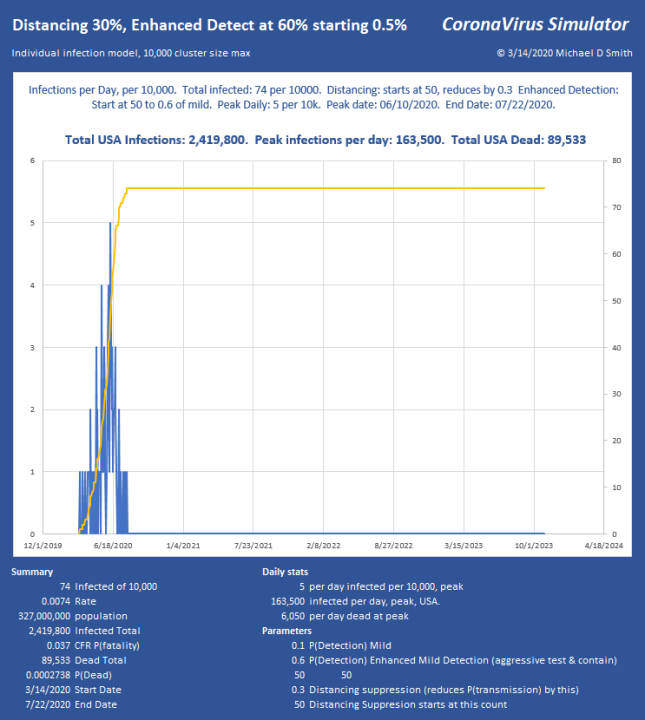
Now we have reduced the peak to 12,436 per day, which (times 0.06) is 746 ICU beds per day. Doable. But look what happened. At such low suppression, the virus is skipping along the bottom, hanging on. The total infected went up, we lost another 28,000 people, and the event lasts into 2023 with sustained suppression that whole time. Not good. So, let’s try 95% reduction:
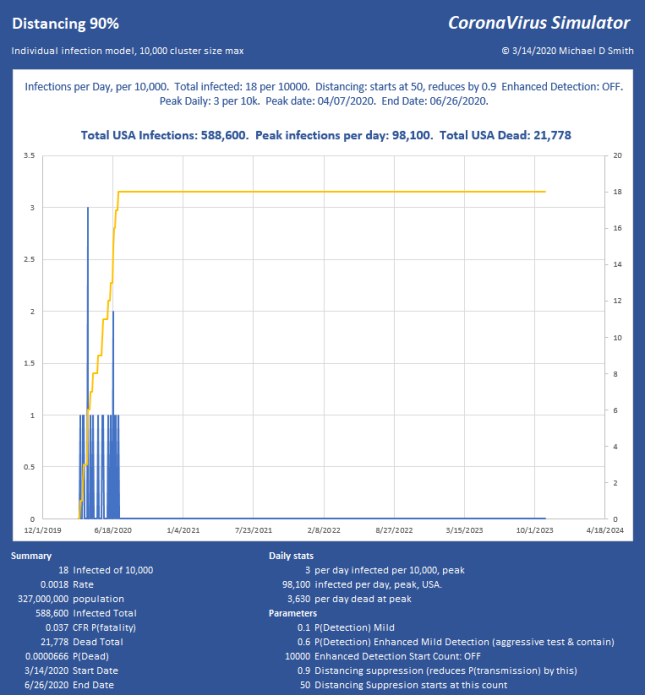
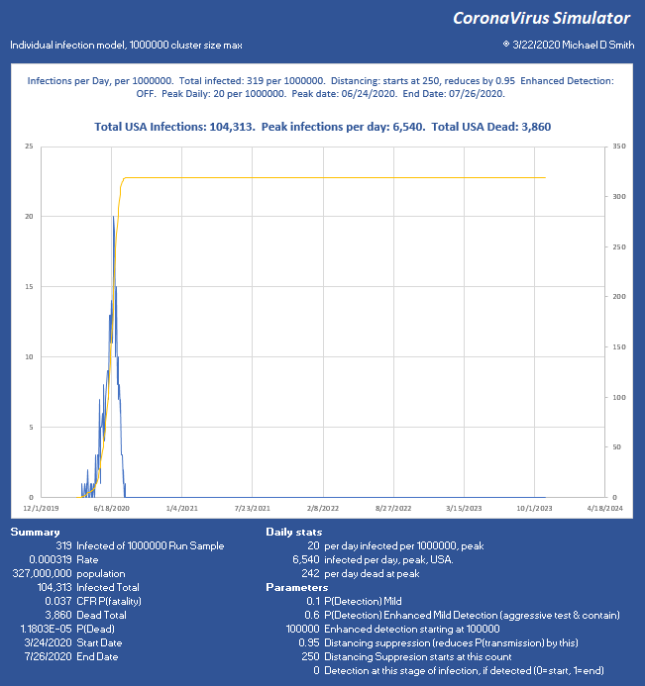 Why Distancing is Important
Why Distancing is Important
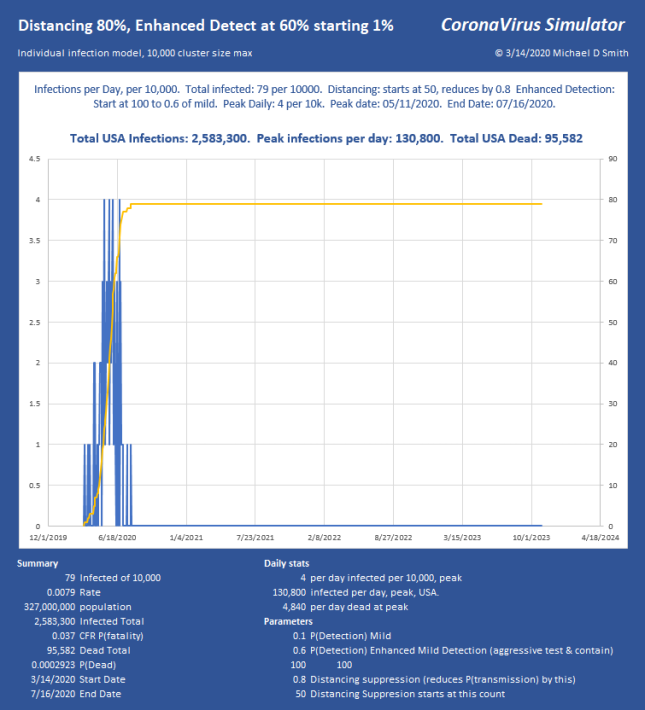
Now we stopped the infection progression at 319 of 1 million, only 69 victims after the moment we hit the brakes! We have the peak at 6540 infections per day, USA, or just under 400 ICU beds per day, sustainable through the peak with the existing medical system, with ease. So while we can run along doing medium suppression, much more aggressive action is far better and faster. Of course, the distribution will not be uniform and large cities will likely be hit much harder than these numbers might indicate.
In these examples, with regard to the dates shown, remember, we’re starting from ONE infection, today, and letting it run. In the above run, it takes from 3/24 to 6/24 to build up to the 250 count (near the peak) THEN we apply suppression, and the progression collapses just 33 days later. The model doesn’t know how to start with 250 right now, it has to generate each infection and give it a serial number and track the progress and collect time stamps of each branch until it fails to progress and stops. I can apply whatever technique I want to it any any point in the progression. But, to be clear, you may need to subtract the growth period from the end dates to see how fast this could really end.
Sensitivity:
The model is very sensitive to factors that increase new hosts. For example, right now the “infection attempts” integer is controlled strictly by the infectious period and the infectious rate, with the period being part of a distribution. If I decide that I want to give it more of a natural feel so that some hosts infect many others while others don’t by adding another distribution, it can have a wildly different answer. Because if you increase the chances of having 5 seeds instead of 2 or 3, even once in a while, that many more new clusters have a good chance of going exponential, so any factor that increases new hosts has a huge impact. The good news is, any factor that diminishes that also has a huge impact! So, by extension, people who ignore measures and infect many others are a really bad feature for the rest of us, extending both the peak and the duration of the pain.
Speed:
A study which I think is very promising (pre-print) by Wölfel et al. describes the shedding rate of the virus. Just after onset, the shedding rate is extremely high but diminishes rapidly so that while virus may be detectable long after illness is over, viable virus capable of reproduction is mostly gone after 9 days. By 7 days, the chance of transmission is down 50%. The chart looks like this:
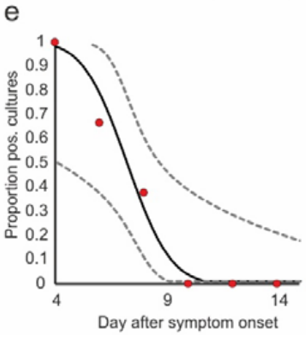
If this is true, and I added it, it will have the effect that the infection is more like a spark than an opportunity period, and transmission will be even more aggressive but shorter lived, which will still be MUCH faster than the current model. In a static population, it would progress like a wave and sweep right through, more like a brush fire than small distributed fires. This could be what is happening now, but I suspect it is somewhere in between. In any case, this will reduce the event duration even more, making the end date very soon if hard suppression actions are taken now. Good thing for the economy.
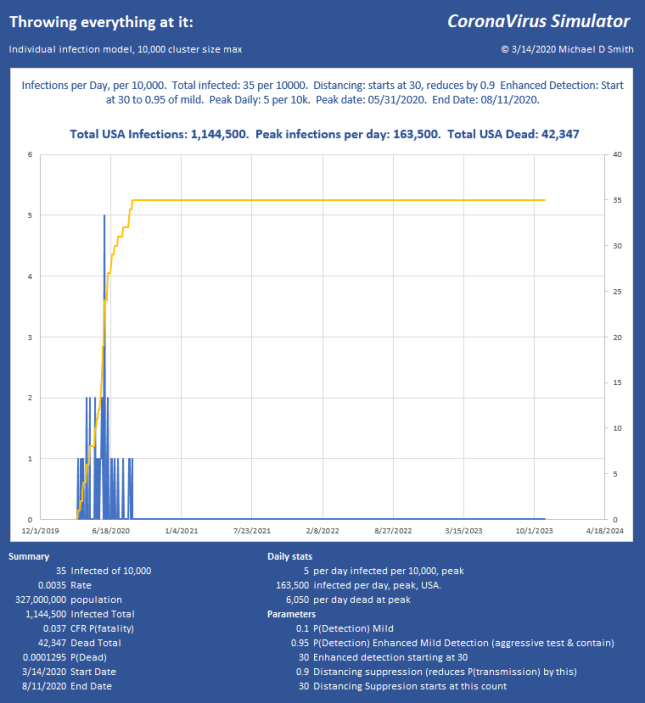
The usual yada yada: These are comparisons, not predictions… This is just a tool, with way too many parameters, many of which are not known precisely. The inputs are values I get from various publications, but I have no idea whether this is how it will play out. I do believe that distancing will work, as long as we only have some small leaks of a few new hosts. There is no reason that most of the US needs to get infected, it all depends on the participation and effectiveness of the suppression. I’m quite convinced though, that any scenario that does not include hard suppression now will either take too long, kill too many, or both.
There are some promising studies going on with other drugs that may make recovery much more likely, which could really help this situation, if high volumes of each are available.
New features
- Individual infection progress and tracking on a Population size up to 1 million.
- Original used uniform distribution for incubation, sickness duration, etc. Now selectable with triangle. Also tried gamma, normal, but incubation in particular needs to have the mode pushed way left to get the median and max to come out correctly to match estimates of a median 5.1 day incubation, with min at 2 and max at 11.5. The cumulative distribution is a little tricky with triangular but I was able to implement it. As suspected, this greatly reduces infection duration of the entire event.
- Sensitivity analysis of any parameter. If there is something you want to try, let me know.














 The chart above shows spurious UHI content of about 0.0033°C per year (chart by Dr. Roy Spencer)
The chart above shows spurious UHI content of about 0.0033°C per year (chart by Dr. Roy Spencer)





















{kind=link}